Faced an interesting bug this week when doing a DRS restore in a dead-net environment ahead of a migration.
Backup was from 11.5.x, and included PLM, SELFCARE, IM_AND_PRESENCE and UCM components.
When doing the restore, the one-step restore process failed, and we reverted to restoring per-server. Again, we faced the same issue, noting the following error message:
ERROR: Unable to restore the data – Cannot find the deployment type, Restore Completed.
The restore failed after about 10 seconds, which made it clear that the restore was connecting to the SFTP server, downloading and parsing the drfComponent.xml file, and finding some error that it didn’t like.
We also noted that during the migration, we had changed the OVA deploy option to the 7.5K OVA, which did have an impact on the disk layout. This forum thread suggested that we may face an issue due to this, and recommended a process of per-component restoring to isolate the root cause:
Following this process, we found that only the SELFCARE component was causing the issue:
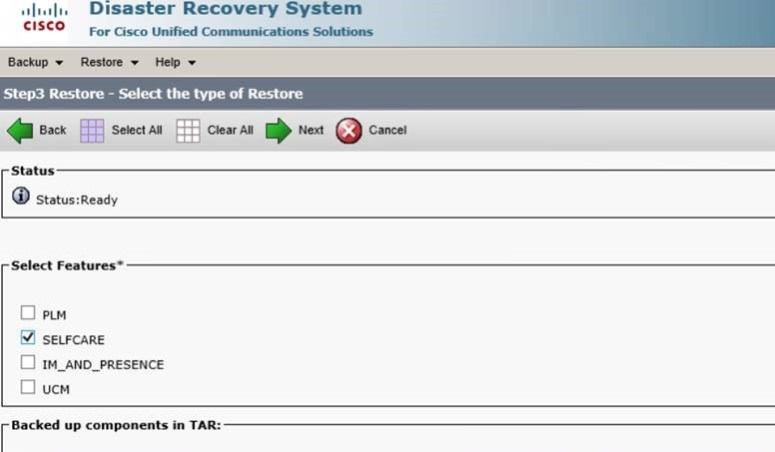


I also noted that drfComponent.xml listed the following for deployment:
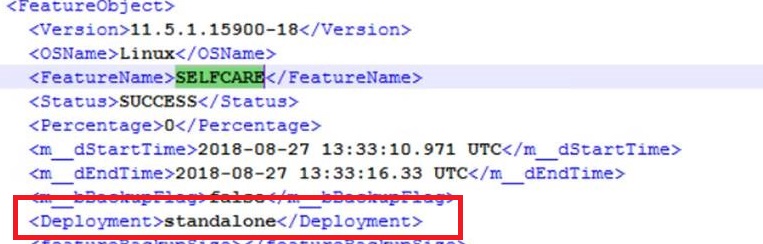
I’m not sure what the “standalone” value explicitly means (the system was a multi-node cluster), but just including it for completeness sake. Some research yielded the following related bugs:
As this was a relatively new component (SELFCARE) to the DRS backup, I was uncertain what actual information was potentially at risk of being lost, or actually what it contained. As we’d pretty much nailed down the cause and had hit diminishing returns from our troubleshooting process, we decided to go for a TAC to confirm…
Managed to complete the TAC case pretty quickly. The answer from TAC on the SELFCARE component was:
After checking from the root we can see the see that PLATFORM and CLM components for the Selfcare and UCM feature are involving the same scripts and functionality. So if the Selfcare feature is not present in DRS page it won’t affect the backup.
Interesting.
Additionally, the defect we faced was a known, but not publically available defect:
The key takeaway here was that patience is a virtue with DRS restore troubleshooting… It is also highly recommended to go through this process in a safe environment, at least for practice, so that one has a good idea of the best steps for troubleshooting, and the timeframes needed if faced with this in an environment down emergency.
