I arrived on site at a remote client picking up a deployment that was done some 18 months ago for additional scope of work. However, when I arrived to begin, I encountered some strange behaviour that I struggled to attribute to anything obvious.
What I saw was:
- High number of AXL connections on CUCM:
admin:utils diagnose test
Log file: platform/log/diag3.log
Starting diagnostic test(s)
===========================
test – disk_space : Passed (available: 1796 MB, used: 12360 MB)
skip – disk_files : This module must be run directly and off hours
test – service_manager : Passed
test – tomcat : Passed
test – tomcat_deadlocks : Passed
test – tomcat_keystore : Passed
test – tomcat_connectors : Passed
test – tomcat_threads : Passed
test – tomcat_memory : Passed
test – tomcat_sessions : Failed – The following web applications have an unusually large number of active sessions: axl. Please collect all of the Tomcat logs for root cause analysis: file get activelog tomcat/logs/*
skip – tomcat_heapdump : This module must be run directly and off hours
test – validate_network : Passed
test – raid : Passed
test – system_info : Passed (Collected system information in diagnostic log)
test – ntp_reachability : Passed
test – ntp_clock_drift : Passed
test – ntp_stratum : Passed
skip – sdl_fragmentation : This module must be run directly and off hours
skip – sdi_fragmentation : This module must be run directly and off hours
- Backups Failing
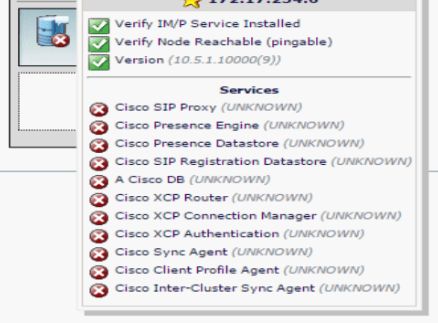
- Jabber services listed as” UNKNOWN” from the GUI, even though listed as “STARTED” from Serviceability and from CLI:
- Immediate Switch-Version failed after an upgrade due to SELinux failing to upgrade correctly, causing differing behaviour on different servers:
– Java errors on login to server and CLI scripts unable to run due to permissions issues
– A Cisco DB service refusing to start!
– Kicked out of ssh session directly after authentication – SELinux issue
The SELinux issue actually prevented a switch-back as this could not be initiated from CLI. To resolve this I had to complete a manual partition switch using the CUCM/CUC Recovery CD as well as a File System Check and Repair!
This was all very, very strange!
Once back to a “stable” platform after the partition swap and file-system check, I again attempted an upgrade, which this time failed:
04/20/2016 19:46:49 upgrade_install.sh|Started auditd…|<LVL::Info>
04/20/2016 19:46:49 upgrade_install.sh|Started setroubleshoot…|<LVL::Info>
04/20/2016 19:46:49 upgrade_install.sh|Changed selinux mode to enforcing|<LVL::Info>
04/20/2016 19:46:49 upgrade_install.sh|Cleaning up rpm_archive…|<LVL::Info>
04/20/2016 19:46:49 upgrade_install.sh|Removing /common/rpm-archive/10.5.2.12901-1|<LVL::Info>
04/20/2016 19:46:50 upgrade_install.sh|File:/usr/local/bin/base_scripts/upgrade_install.sh:604, Function: main(), Upgrade Failed — (1)|<LVL::Error>
04/20/2016 19:46:50 upgrade_install.sh|Parse argument status=upgrade.stage.error|<LVL::Debug>
04/20/2016 19:46:50 upgrade_install.sh|_set_upgrade_status_attribute: status set to upgrade.stage.error|<LVL::Debug>
04/20/2016 19:46:50 upgrade_install.sh|is_upgrade_lock_available: Upgrade lock is not available.|<LVL::Debug>
04/20/2016 19:46:50 upgrade_install.sh|is_upgrade_in_progress: Already locked by this process (pid: 32606).|<LVL::Debug>
04/20/2016 19:46:50 upgrade_install.sh|release_upgrade_lock: Releasing lock (pid: 32606)|<LVL::Debug>
This time, I had selected an immediate switch-version instead of using a 2-stage process after a successful upgrade. Again, I could confirm a successful upgrade:
04/20/2016 19:39:01 post_upgrade|Post Upgrade RTMTFinish|<LVL::Notice>
04/20/2016 19:39:01 post_upgrade|========================= Upgrade complete. Awaiting switch to version. =========================|<LVL::Info>
04/20/2016 19:39:01 upgrade_manager.sh|Post-upgrade processing complete|<LVL::Info>
04/20/2016 19:39:01 upgrade_manager.sh|Application install on inactive partition complete|<LVL::Info>
04/20/2016 19:39:01 upgrade_manager.sh|L2 upgrade… Run selinux_on_inactive_partition|<LVL::Info>
So now, I concentrated on the post-upgrade switch-version logging, and picked up on this:
04/20/2016 19:46:38 upgrade_manager.sh|(CAPTURE) /sbin/restorecon.orig set context /etc/opt/cisco/elm/client/.security/trust_certs/Cisco_Root_CA_M1.pem->system_u:object_r:cisco_etc_t:s0 failed:’Operation not permitted’|<LVL::Debug>
04/20/2016 19:46:38 upgrade_manager.sh|(CAPTURE) /sbin/restorecon.orig set context /etc/opt/cisco/elm/client/.security/trust_certs/Cisco_Root_CA_M1.der->system_u:object_r:cisco_etc_t:s0 failed:’Operation not permitted’|<LVL::Debug>
04/20/2016 19:46:38 upgrade_manager.sh|(CAPTURE) /sbin/restorecon.orig set context /home/sftpuser/sftp_connect.sh->specialuser_u:object_r:user_home_t:s0 failed:’Operation not permitted’|<LVL::Debug>
It was then that I became very confused. These strange issues together all pointed to **certificate expiration**. However, the system had been installed less than 18 months ago, so this didn’t make sense! I checked the certificates and confirmed – all expired. Then it dawned on me. When we had installed the system, we had staged the network and voice at the same time. We’d pointed NTP to the firewall – which must have, prior to go-live, been set as a master by our firewall team … with the wrong date-time! 😦
So, root cause found, but now to resolve?!
Certificates are a tricky business in CUCM since the implementation of Security by Default. I don’t intend to cover this topic here (it’s absolutely huge), but I will say this – changing certificates on CUCM can run the risk of getting you fired.
If you don’t know 100% what you are doing, you could cause an outage that will require serious skill to repair, an emergency TAC engagement, manual phone intervention or a combination of the 3.
So, I now needed to complete Certificate Regeneration on CUCM, CUC and IM&P.
Some notes here:
- My cluster was not in Mixed Mode – my life just got a whole lot easier!
- The client didn’t have a Private CA, so we were forced to use Self-Signed. A major consideration if you have signed certs.
- I was working on a BE6K – with no redundancy – so for me… ITL files are going to be an issue. I must to do a “Pre- 8.0 Rollback” and blank all the ITL files before I start.
- Multi-App integrations are probably going to require manual certificate download/import between clusters for IM&P
Following the above process, I carefully:
- Blanked all ITL files, with necessary TVS and TFTP service restarts as required
- Stopped TFTP Services
- Regenerated all applicable certificates as per the above guide
- Manually deleted “-trust” certificates as per the guide – I preferred the GUI to the CLI for this – watch out for related bugs in the above guide.
- Restarted all applicable services
- Removed Pre-8.0 Rollback Enterprise Parameter ITL blanking
- Again, restarted TVS and TFTP services
- Imported regenerated certs for intra- and inter-cluster communications
An Important Note:
When restart TFTP, always wait 5-10mins for the TFTP files to rebuild on the server. More haste, Less-Job-Come-Monday.
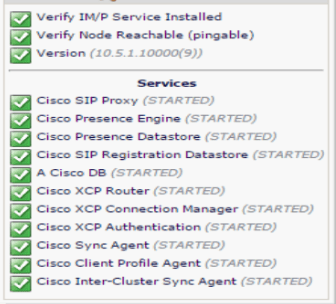
Rebooted IM&P, and immediately saw that all the affected IM&P services were listed correctly:
Helpful links on SBD (Security by Default) and CUOS Certificates in General:
- https://supportforums.cisco.com/document/68701/communications-manager-security-default-and-itl-operation-and-troubleshooting
- http://www.cisco.com/c/en/us/support/docs/unified-communications/unified-communications-manager-callmanager/200199-CUCM-Certificate-Regeneration-Renewal-Pr.html
- https://supportforums.cisco.com/document/60716/migrating-ip-phones-between-clusters-cucm-8-and-itl-files
- https://supportforums.cisco.com/document/12139776/unified-communications-manager-itl-enhancements-1001#anc5
- http://www.cisco.com/c/en/us/support/docs/voice-unified-communications/unified-communications-manager-callmanager/116232-technote-sbd-00.html
- https://www.ciscolive.com/online/connect/sessionDetail.ww?SESSION_ID=3929
- https://www.youtube.com/watch?v=xTnS7HEADdU&list=PLFuOESqSTxEvZChqWgAJanctohRMe99CR&index=9
Check out the ITLRecovery enhancements in 10.x and above!
#dontcalltac
